





現在この本でスクレイピングの勉強中です↓

先日ちょうどスクレイピングをする機会があり、この本のとおりにやったらできたので
その事について書いていきます。
スクレイピングでWebサイトから画像をダウンロードしてみた。
私は子育てブログもやっているのですが、
先日あるWebサイトから画像をいくつかダウンロードする機会がありました。
そのサイトがこちら↓
このサイトの人気ランキング1~4位までの画像です。
最初は普通に一つ一つダウンロードしようと思ったのですが、
「まてよ、これスクレイピングでできるんじゃね?」
と思い、スクレイピングに挑戦してみることに。
ちょうど本にもスクレイピングで画像をダウンロードする方法が載っていたのです。
Webサイトでスクレイピングが禁止されているか確認する方法。
さっそくコードを書きたいところですが、
その前に、このWebサイトがスクレイピング禁止してないのかを確認する必要があります。
確認方法は、
- まずこのWebサイトの利用規約(だいたいフッターにある)を開く。
- CTRL+Fを押して検索ボックスを開く。
- 検索ボックスに「自動」「クローリング」「スクレイピング」「ロボット」などと入力し、ヒットしなければOK。
という手順です。
この方法は、こちらのYouTube動画を参考にさせていただきました↓
selectメソッドで取得できる上限を設けるには?limitは使える?
ではコードを書いていきます。
基本的に本に書いてあるとおりのコードでOK。
URLを変更して、CSSセレクタを変更して…。
ただ、このWebページには1~10位まで載っているので、普通にやると1~10位までの画像が取得できてしまいます。
でも欲しいのは1~4位までの画像。
「取り出す件数に上限を設けるにはどうすればいいんだろう?」
と思い本で調べると
find_allメソッドの場合は
find_all(タグ名,limit=4)
というように
第2引数にlimit=4とやれば先頭4件のみ取得できるみたいですが、
selectメソッドの場合は書いてません。
「スクレイピング select 上限」「Python select limit」などとググっても出てきません。
たぶんselectの場合も使えるんだろう、と思い、試しに
select(セレクタ,limit=4)
とやって実行してみると、
できました!
が一件しか取り出せてない。
なぜだろう?
よくみてみると、セレクタにnth-child(1)と書いてあります↓

これは一番目という意味。
なるほど、これが原因か。
HTML/CSSを学習してたのがここで活きました。
このnth-child(1)の部分を削除して再度実行してみると、
できました!
見事に先頭4件の画像がダウンロードできてます!↓
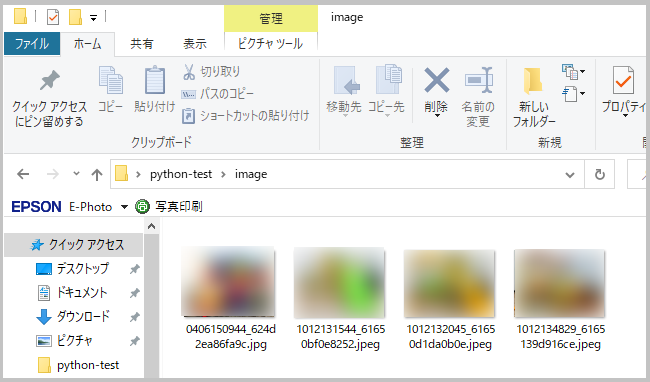
しかも自動的に新規作成されたimageフォルダに入ってる↓
すげー。俺、プログラマーみたい(笑)
どうやらselectメソッドの場合もlimitは使えるみたいですね。
いちおう成功したコードを載せておきます↓
import time
from pathlib import Path
from urllib.parse import urljoin
import requests
from bs4 import BeautifulSoup
url='https://circle-toys.jp/'
res=requests.get(url)
soup=BeautifulSoup(res.text,'html.parser')
books=soup.select('div.top-ranking > div > ul > li > a > span > span > img',limit=4)
img_dir=Path('./image')
img_dir.mkdir(exist_ok=True)
for book in books:
url_rel=book['src']
url_abs=urljoin(url,url_rel)
img_res=requests.get(url_abs)
img_name=Path(url_abs).name
img_file_path=img_dir / img_name
img_file_path.write_bytes(img_res.content)
time.sleep(1)
スクレイピング楽しいですね。
難しいですが、何度かやってるうちに覚えてきます。
